
这份 高性能系统知识体系 面向后端学习、系统设计和面试复习,围绕“减少延迟、提升吞吐、削峰填谷、降低数据库压力、优化数据访问路径”整理本站高性能相关文章。
2026/5/28大约 5 分钟
这份 高性能系统知识体系 面向后端学习、系统设计和面试复习,围绕“减少延迟、提升吞吐、削峰填谷、降低数据库压力、优化数据访问路径”整理本站高性能相关文章。
CDN 全称是 Content Delivery Network/Content Distribution Network,翻译过的意思是 内容分发网络 。
我们可以将内容分发网络拆开来看:
数据冷热分离是指根据数据的访问频率和业务重要性,将数据划分为冷数据和热数据,并分别存储在不同性能和成本的存储介质中的架构策略。
这种架构的核心目标有三个:
查询偏移量过大的场景我们称为深度分页,这会导致查询性能较低,例如:
# MySQL 在无法利用索引的情况下跳过1000000条记录后,再获取10条记录
SELECT * FROM t_order ORDER BY id LIMIT 1000000, 10高性能系统面试不是问你会不会背几个优化手段,而是看你能不能把请求链路拆开:用户请求进来后,哪里可能慢,哪里可能扛不住,哪里需要削峰,哪里需要减少数据库压力,哪里需要用监控和压测验证效果。
这篇文章把 JavaGuide 现有高性能相关文章串成一条面试复习路线,适合准备后端开发、系统设计和架构设计相关面试。
高性能问题通常可以按请求链路拆成 4 层:
负载均衡 指的是将用户请求分摊到不同的服务器上处理,以提高系统整体的并发处理能力以及可靠性。负载均衡服务可以有由专门的软件或者硬件来完成,一般情况下,硬件的性能更好,软件的价格更便宜(后文会详细介绍到)。
下图是《Java 面试指北》 「高并发篇」中的一篇文章的配图,从图中可以看出,系统的商品服务部署了多份在不同的服务器上,为了实现访问商品服务请求的分流,我们用到了负载均衡。
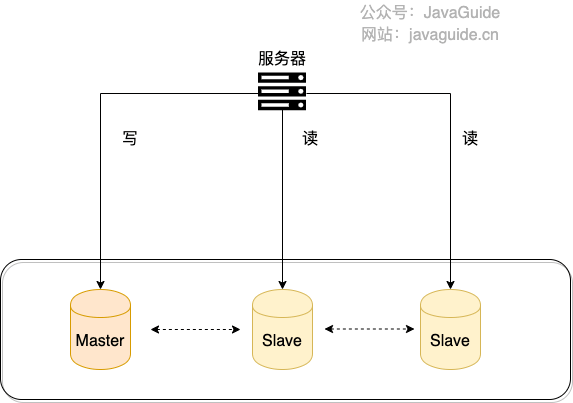
顾名思义,根据读写分离的名字,我们就可以知道:读写分离主要是为了将对数据库的读写操作分散到不同的数据库节点上。 这样的话,就能够小幅提升写性能,大幅提升读性能。
我简单画了一张图来帮助不太清楚读写分离的小伙伴理解。
SELECT * 会消耗更多的 CPU。SELECT * 无用字段增加网络带宽资源消耗,增加数据传输时间,尤其是大字段(如 varchar、blob、text)。SELECT * 无法使用 MySQL 优化器覆盖索引的优化(基于 MySQL 优化器的“覆盖索引”策略又是速度极快,效率极高,业界极为推荐的查询优化方式)SELECT <字段列表> 可减少表结构变更带来的影响。消息队列是高性能和高可用系统里都非常常见的中间件,主要用于异步处理、应用解耦、削峰填谷和流量缓冲。学习消息队列时,不能只背 Kafka、RocketMQ、RabbitMQ 的特性,更要理解消息可靠性、顺序性、幂等性、积压处理和技术选型。